
Back in a post in November 2012 we announced that EDINA is redeveloping the existing SUNCAT search platform. We also gave you a preview of the new design and now we want to follow these posts up with more technical information about the new architecture.
New Search Platform
The cornerstone to the SUNCAT service is the ability to search for libraries’ MARC records and we wanted this to be as efficient as possible within the new architecture. We have therefore decided to use the open source enterprise search platform ‘Solr’ from the Apache Software foundation given its popularity and feature set.
We have established a workflow, which exports records from Aleph (currently used for loading and de-duplication of libraries’ serial records) and indexes these records within Solr.
The diagram below illustrates the process:
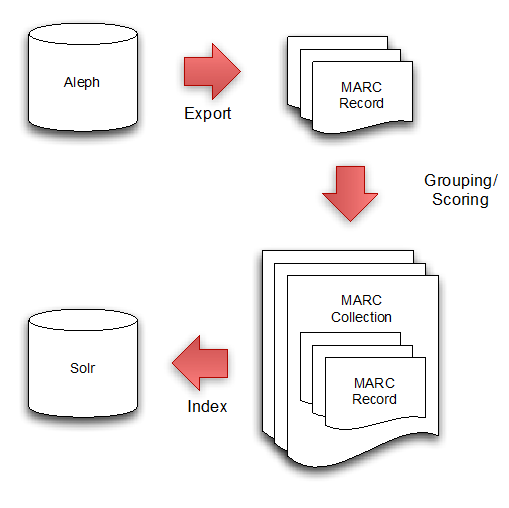
Individual MARC records are exported from Aleph and these are then grouped into MARC collections. A MARC collection consists of records from the libraries holding a particular serial.
These MARC collections are then indexed in Solr using a modified version of the open source solrmarc code.
Currently the Solr index consists of over 5 million individual library MARC records and in terms of storage sizes, this equates to over 30GB on disk.
New Interface
Storing all of the records in Solr however is only part of the new architecture. We are developing a new user interface for the SUNCAT service, taking the opportunity to also incorporate some new features that exploit the power of Solr.
A combination of the Java programming language, Groovy programming language and the Grails framework has been chosen as the software stack as it enables a rapid development process and also leverages the experience of developers within EDINA.
Grails follows the highly popular software design pattern of Model View Controller, which allows separation of concerns and a clean software design.
The following diagram illustrates at a very high level the architecture we are using and how Solr is involved:

We are developing a number of ‘controllers’, which are used to process user requests and issue queries to Solr as and when required. These controllers are designed for specific tasks e.g.
• Handling search requests
• Handling API requests
• Handling requests to view details of a specific MARC record etc.
We also have a number of templates that comprise the ‘views’ of the new system. When a controller has completed the processing of the user request and it is ready to return something to the user (e.g. a web page), it uses the relevant template and injects the correct data e.g. the search results. Using a template approach for all of the views of the system provides a huge amount of flexibility as we have full control of all visual aspects of the service and we can even support different output formats based on the user request e.g. supporting HTML, XML, JSON etc.
Enabling Searching at Library Level
We are also spending time in constructing a database to store institution, library and location data and integrating this within the new user interface in-order to allow users to perform more detailed searches within SUNCAT. For example searches can be performed at the library level whereas previously users could only search at the institutional level. We have also tagged every library with its GPS coordinates, which allows us to show all SUNCAT contributing libraries in a map interface and will allow proximity based searching in the forthcoming SUNCAT mobile application for iOS.
We will be keeping you up to date with more posts, about the redevelopment and the mobile app, to follow over the next few months.