It is not possible to give a definitive answer, however it is important to look at this technology which has been causing a stir in the informatics field.
Basically a triplestore is a purpose-built database for the storage and retrieval of triples (Jack Rusher, Semantic Web Advanced Development for Europe). Rather than highlighting the main features of a triplestore (by way of making a comparison to a traditional relational database), we will give a brief overview of the how and why of choosing, installing, and maintaining a triplestore, giving a practical example not only of the installation phase but also of the graphical interface customization and some security policies that should be considered for the SPARQL endpoint server.
Choosing the application
The first task, obviously, is choosing the triplestore application.
Following Richard Wallis’ advice (see reference) 4Store was considered a good tool, useful for our needs. There are a number of reasons why we like this application: firstly, as Richard says, it is a open source project and it “comes from an environment where it was the base platform for a successful commercial business, so it should workâ€�. In addition, as their website suggest, 4store’s main strengths are its performance, scalability and stability.
It may not provide many features beyond RDF storage and SPARQL queries, but if your are looking for a scalable, secure, fast and efficient RDF store, then 4store should be on your shortlist. We did investigate other products (such as Virtuoso) but none were as simple and efficient as 4Store.
Hardware platform
At EDINA, we tend to manage our services in hosted systems (similar to the concept that many web-hosting companies use.)
After considering the application framework for a SPARQL service, and various options of how triplestores could be used within EDINA, we decided to create an independent host for the 4Store application. This would allow us to both keep the application independent of other services and allow us to evaluate the performance of the triplestore.
It was configured with the following features:
- 64bit CPU
- 4 GB of RAM (with the possibility to increase this amount if needed)
- Linux (64-bit RedHat Enterprise Level 6)
Application installation
At EDINA, we try to install services as a local (non-root) user. This allows us the option of multiple independent services within one host, and reduces the chance that an “exploit� (or cyber break-in) gains significant access to the hosts operating system.
Although some libraries were installed at system level, almost everything was installed at user-level. Overall, the 4Store installation was quick and easy to configure: installing the software as normal user required the installation paths to be specified (ie --prefix=~~~), however there were no significant challenges. We did fall foul when installing the raptor and rasqal libraries (the first provides a set of parsers that generate triples, while the second is useful to handle query language syntaxes [such as SPARQL]): there are fundamental differences between v1 & v2 – and we required v2.
Configuration and load data
Once finished the installation, 4Store is ready to store data.
- The first operation consists to set up a dataset, which (for this example) we will call “ori�:
$ 4s-backend-setup ori
- then we start the database with the following command:
$ 4s-backend ori
- Next we need to load the triples from the file data set. This step could take a while, depending on the system and on the amount of data.
$ 4s-import -v ori -m http://localhost:8001/data/ori /path/to/datafile/file.ttl
- This command line includes some options useful for the storing process. 4store’s import command produces no output by default unless something goes wrong (ref: 4Store website).
- Since we would like more verbose feedback on how the import is progressing, or just some reassurance that it’s doing something at all, we add the option “-vâ€�.
- The option “-mâ€� (or “–modelâ€�) defines the the model URI: It is, effectively, a namespace. Every time we import data, 4Store defines a model useful to map a SPARQL graph for the imported data. By default the name of your imported model (SPARQL graph) in 4store will be a file (URI derived from the import filename) but we can use the –model flag to override this with any other URI.
The model definition is important when looking to do data-replacement:
$ 4s-import -v ori -m http://localhost:8001/data/ori /path/to/datafile/file2.ttl
By specifying the same model, we replace all the data present in the “ori� dataset with the information contained in the new file.
Having imported the data, the server is ready to be queried, however this is only via local (command-line) clients. To be useful, we need to start an HTTP server to access the data store.
4Store includes a simple SPARQL HTTP protocol server, which can answer SPARQL queries using the standard SPARQL HTTP query protocol among other features.
$ 4s-httpd -p 1234 ori
will start a server on port 1234 which responds to queries for the 4Store database named “ori�.
If you have several 4store databases they will need to run on separate ports.
HTTP Interface for the SPARQL server
Once the server is running we can see an overview page from a web browser at http://my.host.com:1234/status/
There is a simple HTML query interface at http://my.host.com:1234/test/and a machine2machine (m2m) SPARQL endpoint at http://my.host.com:1234/sparql/
These last two links provide the means to execute some queries to retrieve information present in the database. Note that neither interface allow INSERT, DELETE, or LOAD functions, or any other function which could modify the data into the database.
You can send SPARQL 1.1 Update requests to http://my.host.com:1234/update/, and you can add or remove RDF graphs using a RESTful interface at the URI http://my.host.com:1234/data/
GUI Interface
The default test interface, whilst usable, is not particularly welcoming.
We wanted to provide a more powerful, and visually more appealing, tool that could allow to query the SPARQL endpoint without affect the 4Store performance. From the Developer Days promoted by JISC and Dev8D, we were aware of Dave Challis’ SPARQLfront project. SPARQLfront is a PHP and javascript based frontend to RDF SPARQL endpoints. It uses a modified version of ARC2 (a nice PHP RDF library) for most of the functionality, Skeleton to provide the basic HTML and stylesheets, and CodeMirror to provide syntax highlighting for SPARQL.
We installed, configured and customized SPARQLfront under the default system Apache2/PHP server:Â http://my.host.com/endpoint/
The main features of this tool are the highlighted syntax that help during the query composition and the chance to select different output formats.
Security
EDINA is very conscious of security issues relating to services (as noted, we run services as non-root where possible).
It is desirable to block access to the anything that allows modification to the 4Store dataset, however the 4Store server itself provides no Access Control Lists – therefore is unable to block update and data connections directly. The simplest way to block these connections is to use a reverse-proxy in the Apache2 server to pass on calls we do want to allow connect to the 4Store server, and completely block direct access to the 4Store server using a firewall.
Thus, we added proxy-pass configuration to the apache server:
#--Reverse Proxy--
ProxyPass /sparql http://localhost:1234/sparql
ProxyPassReverse /sparql http://localhost:1234/sparql
ProxyPass /status http://localhost:1234/status
ProxyPassReverse /status http://localhost:1234/status
ProxyPass /test http://localhost:1234/test
ProxyPassReverse /test http://localhost:1234/test
Note: do NOT enable proxyRequests or proxyVia as this opens your server as a “forwarding� proxy to all-and-sundry using your host to access anything on the web! (see the Apache documentation)
We then use the Firewall to ensure that all ports we are not using are blocked, whilst allowing localhost to connect to port 1234:
# allow localhost to do everything
iptables -A INPUT -i lo -j ACCEPT
iptables -A OUTPUT -o lo -j ACCEPT
# allow connections to port 80 (http) & port 22 (ssh)
iptables -A INPUT -p tcp -m multiport -d 12.23.34.45 --destination-ports 22,80 -m state --state NEW -j ACCEPT
Your existing firewall may already have a more complex configuration, or may be configured using a GUI. Whichever way, you need to allow localhost to connect to port 1234, and everything else to be blocked from most things (especially 1234!)
–
Cesare



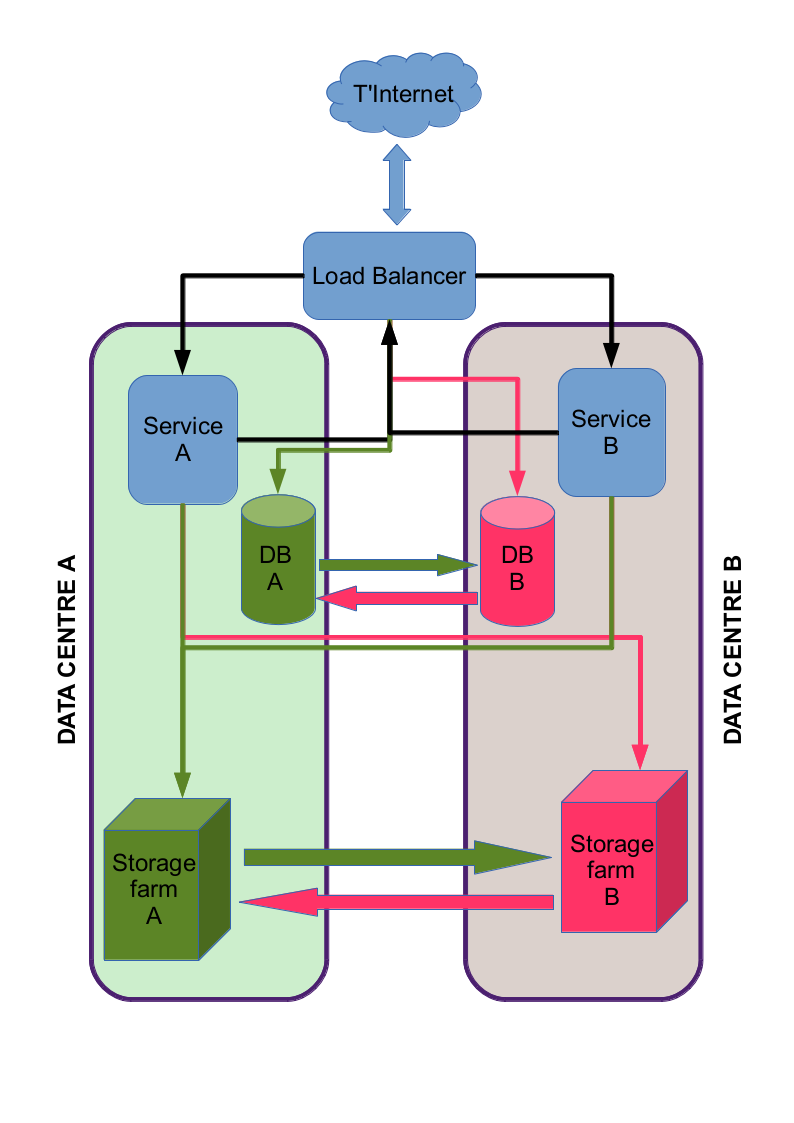 Again, RJB needs more: as well as storing information in the database, the service also writes files do disk. Here at EDINA, we make use of Storage Area Network (SAN) systems – which means we mount a chunk of disk space into the file-system, across the network.
Again, RJB needs more: as well as storing information in the database, the service also writes files do disk. Here at EDINA, we make use of Storage Area Network (SAN) systems – which means we mount a chunk of disk space into the file-system, across the network.

